When you connect to your Autonomous Database, you get to choose from some predefined services. The services available depends on whether you are using a transaction processing (ATP) or a data warehouse instance (ADW) of the database, but for example, for an ATP database you get the following:
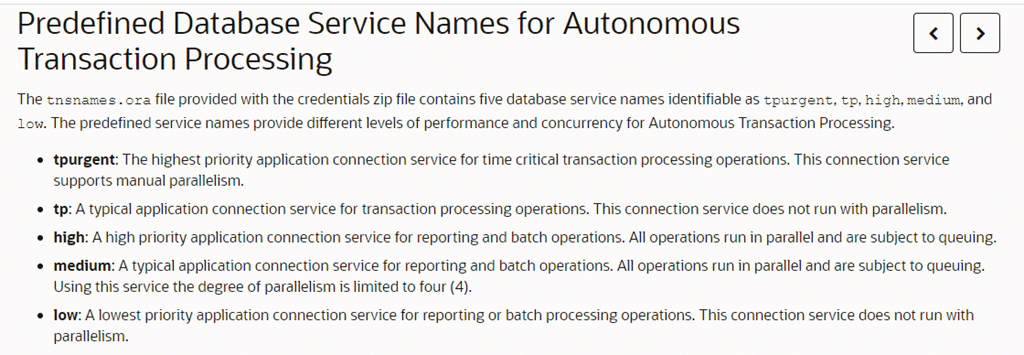
Note: This is a screen of the docs as of time of writing this post. Over time, that may change so always be sure to consult the docs directly in future.
Naturally you’re probably going to be using TP for your day to day applications, which does not run with any parallelism. However from time to time, you might have an occasional need to run something in parallel, but you still want it to be within the confines of typical application usage. For example, your application might be showing data from a materialized view, but an authorised user might be entitled to conduct an on-demand full refresh of that materialized view if they need it reflect the current state of the underlying raw data. Thus within the application, you might want to allow them to refresh that materialized view via a button click but also enlist all the power of parallel processing for the query that (re)generates that materialized view to make it as quick as possible.
One of the cool things with ATP/ADW is that you can now accomplish this by temporarily changing your consumer group for these ad-hoc operations. The DBMS_SESSION package lets you change the consumer group without requiring you to reconnect to a different service. For example, let’s assume I have a huge table and an incredibly large join on that table to yield a result:
SQL> create table t as select d.* from dba_Objects d,
2 ( select 1 from dual connect by level <= 100 );
Table created.
SQL> explain plan for
2 select t5.owner, t3.object_type, count(*)
3 from
4 t t1,
5 t t2,
6 t t3,
7 t t4,
8 t t5,
9 t t6
10 where t1.object_id = t2.object_id
11 and t2.object_id = t3.object_id
12 and t3.object_id = t4.object_id
13 and t4.object_id = t5.object_id
14 and t5.object_id = t6.object_id
15 group by t5.owner, t3.object_type;
Explained.
Assuming I’m connecting to the default TP service in ATP, this query runs in serial even though its a 6-way join on a 3.5million row table.
SQL> SELECT * from dbms_xplan.display();
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------
Plan hash value: 632967984
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 821 | 39408 | | 85M (51)| 00:55:28 |
| 1 | HASH GROUP BY | | 821 | 39408 | | 85M (51)| 00:55:28 |
|* 2 | HASH JOIN | | 688G| 30T| 57M| 46M (10)| 00:30:12 |
| 3 | TABLE ACCESS STORAGE FULL | T | 3558K| 16M| | 818 (5)| 00:00:01 |
|* 4 | HASH JOIN | | 6838M| 273G| 57M| 43M (5)| 00:28:03 |
| 5 | TABLE ACCESS STORAGE FULL | T | 3558K| 16M| | 818 (5)| 00:00:01 |
|* 6 | HASH JOIN | | 67M| 2461M| 23M| 43M (5)| 00:28:01 |
| 7 | VIEW | VW_GBF_71 | 674K| 16M| | 43M (5)| 00:28:01 |
| 8 | HASH GROUP BY | | 674K| 14M| 945G| 43M (5)| 00:28:01 |
|* 9 | HASH JOIN | | 36G| 738G| 57M| 150K (79)| 00:00:06 |
| 10 | TABLE ACCESS STORAGE FULL | T | 3558K| 16M| | 818 (5)| 00:00:01 |
|* 11 | HASH JOIN | | 358M| 5807M| 57M| 3228 (39)| 00:00:01 |
| 12 | TABLE ACCESS STORAGE FULL| T | 3558K| 16M| | 818 (5)| 00:00:01 |
| 13 | TABLE ACCESS STORAGE FULL| T | 3558K| 40M| | 818 (5)| 00:00:01 |
| 14 | TABLE ACCESS STORAGE FULL | T | 3558K| 44M| | 822 (6)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID")
4 - access("T2"."OBJECT_ID"="T3"."OBJECT_ID")
6 - access("T3"."OBJECT_ID"="ITEM_1")
9 - access("T4"."OBJECT_ID"="T5"."OBJECT_ID")
11 - access("T5"."OBJECT_ID"="T6"."OBJECT_ID")
30 rows selected.
And for the vast majority of queries in applications connecting via the TP service, this is the correct way to go. A big query alone is not really justification to let your user community all go hammer-and-tongs smashing away at parallel queries. But perhaps for a suitably authorised user, you want to permit them to have more resources available to them. As I mentioned before, it could be refreshing a materialized view for the benefit of all other users. We can change the consumer group to allow this:
SQL> variable x varchar2(100)
SQL> exec dbms_session.switch_current_consumer_group('HIGH',:x,true);
PL/SQL procedure successfully completed.
Now the execution plan reveals the additional parallel facilities that have become available
SQL> explain plan for ...
Explained.
SQL> SELECT * from dbms_xplan.display();
-----------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 821 | 41871 | | 22M (10)| 00:14:53 | | | |
| 1 | PX COORDINATOR | | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10008 | 821 | 41871 | | 22M (10)| 00:14:53 | Q1,08 | P->S | QC (RAND) |
| 3 | HASH GROUP BY | | 821 | 41871 | | 22M (10)| 00:14:53 | Q1,08 | PCWP | |
| 4 | PX RECEIVE | | 821 | 41871 | | 22M (10)| 00:14:53 | Q1,08 | PCWP | |
| 5 | PX SEND HASH | :TQ10007 | 821 | 41871 | | 22M (10)| 00:14:53 | Q1,07 | P->P | HASH |
| 6 | HASH GROUP BY | | 821 | 41871 | | 22M (10)| 00:14:53 | Q1,07 | PCWP | |
|* 7 | HASH JOIN | | 20M| 997M| | 22M (10)| 00:14:53 | Q1,07 | PCWP | |
| 8 | VIEW | VW_GBF_72 | 674K| 16M| | 11M (10)| 00:07:21 | Q1,07 | PCWP | |
| 9 | HASH GROUP BY | | 674K| 14M| 945G| 11M (10)| 00:07:21 | Q1,07 | PCWP | |
| 10 | PX RECEIVE | | 674K| 14M| | 11M (10)| 00:07:21 | Q1,07 | PCWP | |
| 11 | PX SEND HASH | :TQ10005 | 674K| 14M| | 11M (10)| 00:07:21 | Q1,05 | P->P | HASH |
| 12 | HASH GROUP BY | | 674K| 14M| 945G| 11M (10)| 00:07:21 | Q1,05 | PCWP | |
|* 13 | HASH JOIN | | 36G| 738G| | 65679 (99)| 00:00:03 | Q1,05 | PCWP | |
| 14 | PX RECEIVE | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,05 | PCWP | |
| 15 | PX SEND BROADCAST | :TQ10002 | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,02 | P->P | BROADCAST |
| 16 | PX BLOCK ITERATOR | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,02 | PCWC | |
| 17 | TABLE ACCESS STORAGE FULL | T | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,02 | PCWP | |
|* 18 | HASH JOIN | | 358M| 5807M| | 1533 (44)| 00:00:01 | Q1,05 | PCWP | |
| 19 | PX BLOCK ITERATOR | | 3558K| 40M| | 446 (3)| 00:00:01 | Q1,05 | PCWC | |
| 20 | TABLE ACCESS STORAGE FULL | T | 3558K| 40M| | 446 (3)| 00:00:01 | Q1,05 | PCWP | |
| 21 | PX RECEIVE | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,05 | PCWP | |
| 22 | PX SEND BROADCAST | :TQ10003 | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,03 | P->P | BROADCAST |
| 23 | PX BLOCK ITERATOR | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,03 | PCWC | |
| 24 | TABLE ACCESS STORAGE FULL | T | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,03 | PCWP | |
| 25 | PX RECEIVE | | 1074K| 26M| | 11M (9)| 00:07:32 | Q1,07 | PCWP | |
| 26 | PX SEND BROADCAST | :TQ10006 | 1074K| 26M| | 11M (9)| 00:07:32 | Q1,06 | P->P | BROADCAST |
| 27 | VIEW | VW_GBC_71 | 1074K| 26M| | 11M (9)| 00:07:32 | Q1,06 | PCWP | |
| 28 | HASH GROUP BY | | 1074K| 23M| 1078G| 11M (9)| 00:07:32 | Q1,06 | PCWP | |
| 29 | PX RECEIVE | | 1074K| 23M| | 11M (9)| 00:07:32 | Q1,06 | PCWP | |
| 30 | PX SEND HASH | :TQ10004 | 1074K| 23M| | 11M (9)| 00:07:32 | Q1,04 | P->P | HASH |
| 31 | HASH GROUP BY | | 1074K| 23M| 1078G| 11M (9)| 00:07:32 | Q1,04 | PCWP | |
|* 32 | HASH JOIN | | 36G| 772G| | 65681 (99)| 00:00:03 | Q1,04 | PCWP | |
| 33 | PX RECEIVE | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,04 | PCWP | |
| 34 | PX SEND BROADCAST | :TQ10000 | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,00 | P->P | BROADCAST |
| 35 | PX BLOCK ITERATOR | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,00 | PCWC | |
| 36 | TABLE ACCESS STORAGE FULL | T | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,00 | PCWP | |
|* 37 | HASH JOIN | | 358M| 6149M| | 1536 (44)| 00:00:01 | Q1,04 | PCWP | |
| 38 | PX BLOCK ITERATOR | | 3558K| 44M| | 449 (4)| 00:00:01 | Q1,04 | PCWC | |
| 39 | TABLE ACCESS STORAGE FULL | T | 3558K| 44M| | 449 (4)| 00:00:01 | Q1,04 | PCWP | |
| 40 | PX RECEIVE | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,04 | PCWP | |
| 41 | PX SEND BROADCAST | :TQ10001 | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,01 | P->P | BROADCAST |
| 42 | PX BLOCK ITERATOR | | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,01 | PCWC | |
| 43 | TABLE ACCESS STORAGE FULL| T | 3558K| 16M| | 446 (3)| 00:00:01 | Q1,01 | PCWP | |
-----------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("ITEM_1"="ITEM_1")
13 - access("T4"."OBJECT_ID"="T5"."OBJECT_ID")
18 - access("T5"."OBJECT_ID"="T6"."OBJECT_ID")
32 - access("T1"."OBJECT_ID"="T2"."OBJECT_ID")
37 - access("T2"."OBJECT_ID"="T3"."OBJECT_ID")
Note
-----
- automatic DOP: Computed Degree of Parallelism is 2 because of degree limit
63 rows selected.
In my case, my parallel was capped at 2 because I’m running a very small autonomous database. Also, this facility is not just your applications. SQL Developer Web and Application Express also now have support for altering the consumer group for the session should your users need it.
Important Note: Temporarily changing the consumer group is not equivalent to connecting to a different service.
As the docs themselves note:

If you have an application that always runs heavy duty parallel queries and DML, then it naturally makes sense to use an appropriate service that best achieve that. For example, in a data warehouse instance, it would make sense to run the resource intensive Extract-Transform-Load processing in a Medium or High service, but for that same database, users accessing that warehouse data with their Application Express (APEX) applications would do so in the default Low service. Being able to temporarily change the consumer group then adds the benefit of letting perhaps a couple of key APEX region queries to be run in parallel in order to give the best response times to customers, whilst keeping appropriate balance between responsiveness and resource consumption from a holistic perspective. Consult the APEX documentation for how to do this via the “optimizer hint” attribute.
TL;DR: The combination of services and consumer groups gives you more flexibility with both ATP and ADW instances to best serve the needs of your applications and the customers that are using them.




Leave a Reply