At the start of the year, Twitter become all a flutter when people started posting their results for the 1 billion row challenge.

The challenge was thrown out to the community as an exercise in Java processing (because as we know, people love dumping on Java performance) 😀.

My Java interest (and skills) are low so I only had a passing interest in the challenge, besides seeing the results that people been posting. But when it comes to billions of rows, then besides doing benchmarks and the like, then typically the best place for storing data like that is … in a database!
So I posted a quick tweet after I loaded the flat file into the database showing why databases are just so damn cool at dealing with data.
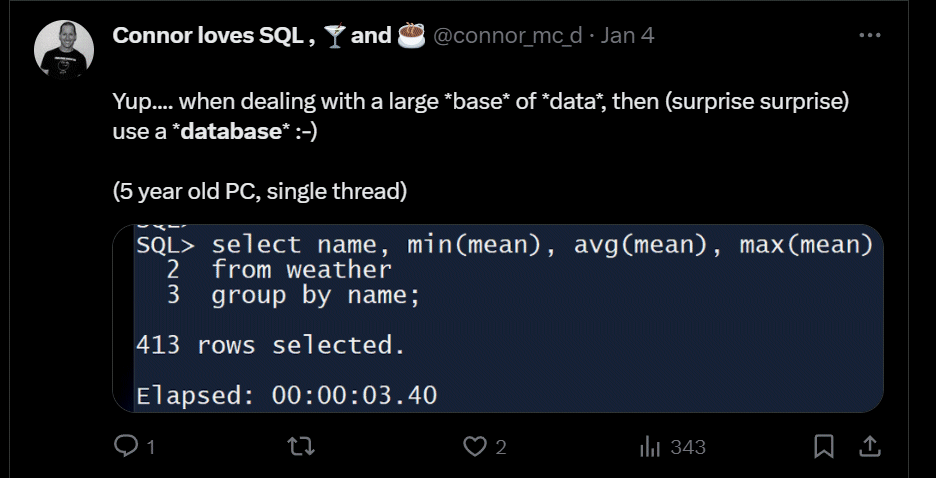
(This tweet got some push back with people saying I was also dumping on Java or trying to hijack the challenge, but my post was purely to elucidate the benefits of processing data in a database. I’d rather write a few lines of SQL that a Java program to process 1 billion rows).
And that’s where I left it. I was supposed to be done with this. 😀
But then friend Gerald posted a far more in-depth exploration of the challenge, looking at how the database (and the database server) can be so easily scaled to process rows incredibly quickly.
Before proceeding, to get the context of what follows, go take a read of the post – its a great read. Go on, I’ll wait 😀
Gerald’s results were in the following table, the key one for me (because I’m a database guy) being the blazingly fast last one.
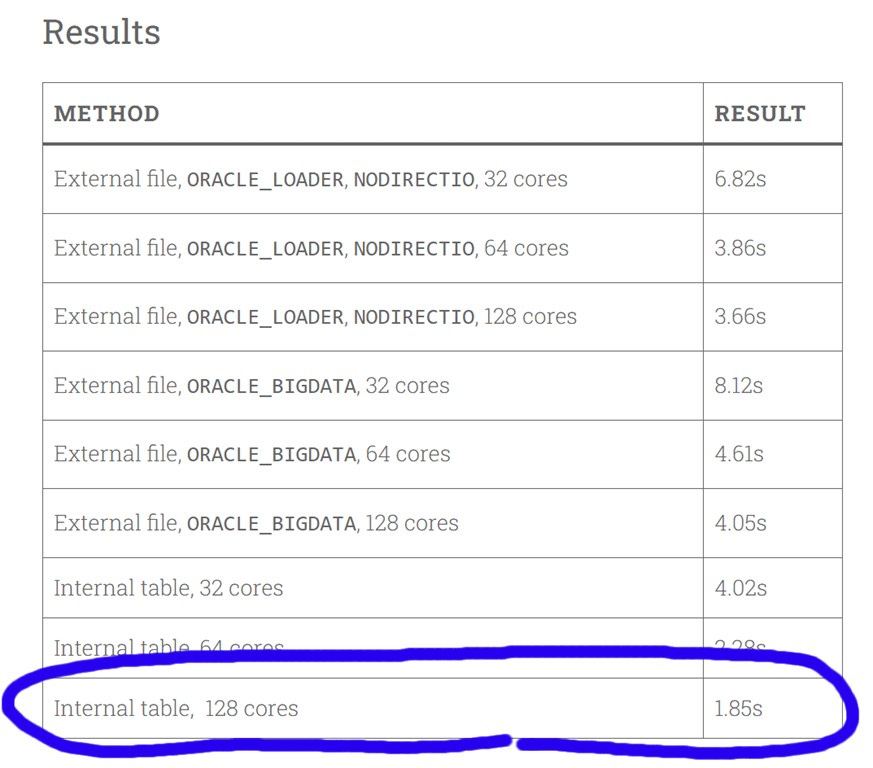
Even then… I was done, nothing more for me to do.
Until Gerald tacked this as a suffix to the his post.

All I can say to that is …

There’s goes my Saturday 😀
So after loading the data into a database table, the first thing I did to improve performance was to compress it with ALTER TABLE MOVE. I then ran Gerald’s query with a parallel degree of 8 on my desktop
SQL> SELECT /*+ PARALLEL(8) */
2 '{' ||
3 LISTAGG(station_name || '=' || min_measurement || '/' ||
4 mean_measurement || '/' || max_measurement, ', ')
5 WITHIN GROUP (ORDER BY station_name) ||
6 '}' AS "1BRC"
7 FROM
8 (SELECT station_name,
9 MIN(measurement) AS min_measurement,
10 ROUND(AVG(measurement), 1) AS mean_measurement,
11 MAX(measurement) AS max_measurement
12 FROM measurements
13 GROUP BY station_name
14 );
1 row selected.
Elapsed: 00:00:02.22
That’s not too bad, but hardly worthy of an addenda to Gerald’s results. Then I recalled our In-Memory technology, which lets you clone relational data into a columnar compressed format that is an excellent source for analytical style queries like this one. It’s literally a simple one liner.
SQL> alter table MEASUREMENTS inmemory;
Table altered.
Once the in-memory store was populated, I could then re-run the query.
SQL> SELECT /*+ PARALLEL(8) */
2 '{' ||
3 LISTAGG(station_name || '=' || min_measurement || '/' ||
4 mean_measurement || '/' || max_measurement, ', ')
5 WITHIN GROUP (ORDER BY station_name) ||
6 '}' AS "1BRC"
7 FROM
8 (SELECT station_name,
9 MIN(measurement) AS min_measurement,
10 ROUND(AVG(measurement), 1) AS mean_measurement,
11 MAX(measurement) AS max_measurement
12 FROM measurements
13 GROUP BY station_name
14 );
1 row selected.
Elapsed: 00:00:00.68
OK, now we are getting places! We are sub-second for a billion rows on a standard desktop machine. I tried several different levels of parallelism but 8 seemed to be the sweet spot. But one thing I did notice was that this optimal level was not saturating my CPU, in fact, it was less than 50% utilised. I could get closer to 100% with higher level of parallelism but the response times were not as good. This gave me an idea – maybe its the memory speed that is the limiting factor here?
So I unloaded the table using DataPump and migrated the table to my gaming laptop. It has a slower CPU, and less cores than my desktop, but one thing it does have…is blazingly fast memory.
And on this machine, we got a result quite special even if I say so myself.
SQL> SELECT /*+ PARALLEL(6) */
2 '{' ||
3 LISTAGG(station_name || '=' || min_measurement || '/' ||
4 mean_measurement || '/' || max_measurement, ', ')
5 WITHIN GROUP (ORDER BY station_name) ||
6 '}' AS "1BRC"
7 FROM
8 (SELECT station_name,
9 MIN(measurement) AS min_measurement,
10 ROUND(AVG(measurement), 1) AS mean_measurement,
11 MAX(measurement) AS max_measurement
12 FROM measurements
13 GROUP BY station_name
14 );
1 row selected.
Elapsed: 00:00:00.43
Less than half a second with only a parallel degree of 6, on a $1000 laptop. Imagine what could be achieved with a genuine server machine with high speed RAM and cores to burn. As Gerald said – there’s is so much cool tech in the Oracle Database just waiting for you to exploit.
A quick note for the doom sayers who will be quick say “Yeah, but what does that In-Memory option cost?” My billion row table consumed around 8GB of RAM in the In-Memory store, and in Oracle Database 19c your first 16GB of In-Memory is free!
Addenda Aug 2025: I recently upgraded my desktop to a faster spec, so some more cores and DDR5 RAM let me squeeze a little more out of it!
SQL> SELECT /*+ PARALLEL(16) */
2 '{' ||
3 LISTAGG(station_name || '=' || min_measurement || '/' ||
4 mean_measurement || '/' || max_measurement, ', ')
5 WITHIN GROUP (ORDER BY station_name) ||
6 '}' AS "1BRC"
7 FROM
8 (SELECT station_name,
9 MIN(measurement) AS min_measurement,
10 ROUND(AVG(measurement), 1) AS mean_measurement,
11 MAX(measurement) AS max_measurement
12 FROM measurements
13 GROUP BY station_name
14 );
1 row selected.
Elapsed: 00:00:00.36
If one third of a second is a big issue for your enterprise … I think you need to revisit your business requirements 🙂




Leave a Reply