At my physical design talk at this year’s Yatra tour in India, one of the demos I do is multiple SQL*Plus sessions all smashing transactions at the database in order to simulate a high volume, high concurrency environment.
After the session, one of the attendees reached out and asked for some details on how I manage the benchmark, and how to manage the general problem of wanting to start multiple processes (each with their own database session) all at the same time.
Hence this post ![]() . I’ve got screen shots here rather the cut/paste-able code, because you can grab the entire set of scripts for this benchmark straight from my github repo. Just look for the scripts
. I’ve got screen shots here rather the cut/paste-able code, because you can grab the entire set of scripts for this benchmark straight from my github repo. Just look for the scripts
- ogb_setup, to create the initial user
- ogb_benchmark, which is the run script for each benchmark worker
- ogb2,3,4,5, which are the examples from the presentation.
The easiest way to stop something in its tracks in any database is with locks. But you need to have something to lock, so in my case, I created a simple table with a row that corresponds to each database process I’m going to launch. For my benchmark demo, I plan to capture elapsed time and transactions per second so I can use this table for this purpose as well.

This gives me a table with 10 rows, where the SEED column contains the values 0 through 9. The database session that will be used to control the benchmark will lock the entire table before any benchmark worker processes are launched:

Now I can launch of each benchmark worker process, using a HOST command or whatever facility I prefer to put asynchronously create multiple database sessions. I’m passing a unique SEED value to each script, which will be used to control the locking.
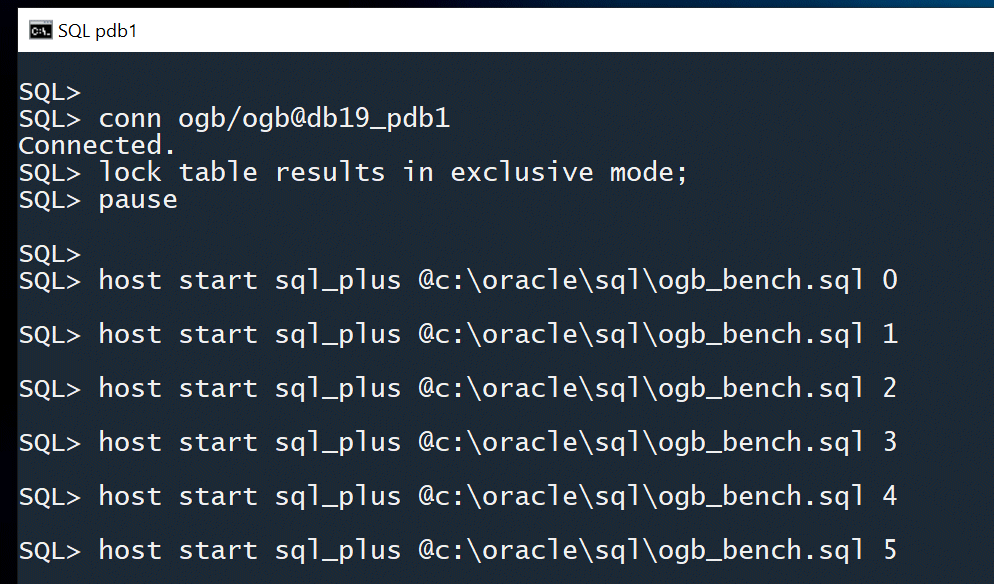
The first thing each of my benchmark processes will do is attempt to lock an its appropriate SEED row in the RESULTS table. This will stop each benchmark worker in its tracks, because of the exclusive lock held at table level in my main calling session.
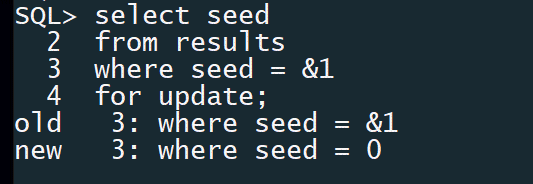
Now I have (in the case above) 6 database sessions all sitting doing nothing because they are blocked from starting due to the exclusive table lock. It is now just a case of issuing a COMMIT in the original session and all the benchmark workers will immediate start at the same time, having successfully grabbed a lock on their own row in the RESULTS table.
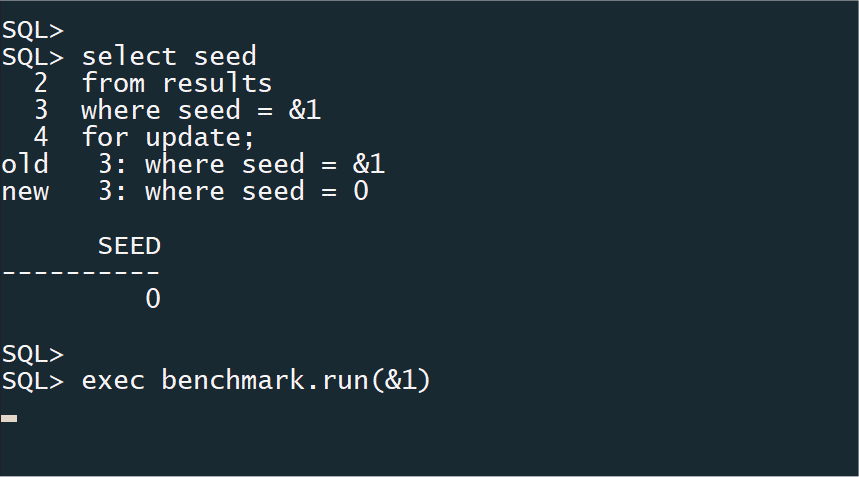
I’m passing the SEED value into my benchmark procedure so that I can update the RESULTS table with things like elapsed time and transactions per second for this particular worker session.
So there you have it – an easy means of controlling the launch of multiple sessions when you want to do benchmarks. Here’s a video of me using this technique for one of the Developer Live talks last year.




Leave a Reply