I happened across an interesting thread on Twitter today which posed the question about when you should intervene with alternative solutions as a table gets larger over time:

It is always good practice to be proactive on thinking about potential future problems before they occur because obviously it is better to solve them before they become a crisis for your customers. Conversely I can already hear you reaching for your keyboards and getting ready to flame me with Knuth quotes ![]()
“The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.”
Anyway, after some others had inquired a little more about typical usage:
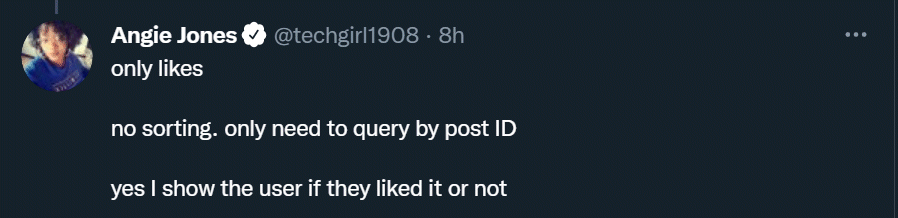
I replied with a claim about relational databases and how they would handle such a table

But as anyone that knows me from AskTom I always recommend that no-one should ever believe anything they read on the internet ![]() unless it comes with some evidence to back it up.
unless it comes with some evidence to back it up.
So here’s a demo I’ve put together on the machine at home, and I’m going to scale up things a tad to really test out just what the limits of using a relational database might be. Based on what I’ve read from the Twitter thread, I’m assuming we have a table that logs every time a user “likes” a post and we’ll store when that like was logged. That gives me this simple structure:
SQL> create table user_likes (
2 user_id int not null,
3 post_id int not null,
4 dt date default sysdate not null
5 ) ;
Table created.
I can’t be sure how close this is to the true requirement/implementation, but lets go with it and see how it handles some load.
I’m going to populate this table under the following assumptions
- We have a user population of 200,000 distinct users (approximately 2x how many followers @techgirl1908 has).
- We have 10,000 posts that might be liked (I don’t know how many posts have really been done)
- To give our table some good volume, we’ll assume every post has been liked by every user
 .
.
Based on this assumption, we can populate the table in random sequence with the following INSERT
SQL> insert /*+ APPEND */ into user_likes
2 with
3 u as (
4 select /*+ materialize */ rownum user_id from dual
5 connect by level <= 200000
6 order by dbms_random.value ),
7 p as (
8 select /*+ materialize */ rownum post_id from dual
9 connect by level <= 10000
10 order by dbms_random.value )
11 select user_id, post_id, sysdate
12 from u,p;
2000000000 rows created.
which yields 2billion rows. Yes, 2 billion. I don’t want to see if 9 million is an issue – I want to know if 200 times that amount is an issue.![]()
Now I’ll index that table based on the following (assumed) requirements
- For a known user and post, do a single row lookup to see if a “like” is present.
- For a known user, show me all of the posts they have liked.
- For a known post, show me all of the users that have liked it
This is why I let every user and every post be present in the table, so that when we benchmark the three above scenarios we wont get any artificially good results due to the non-existence of data. In fact, I’ve done exactly the opposite. Not only will every query we perform in any of the above tests always find some data, they are deliberately more expensive than what we’d expect to find in an real life scenario. Querying posts for a user will always find 10,000 posts! Querying users for a post will always find 200,000 users! I’m going for a worst case scenario for the data we’re using.
I’ll add the two indexes we’ll need.
SQL> alter table user_likes
2 add constraint user_likes_pk primary key
3 ( user_id, post_id );
Table altered.
SQL> create index user_likes_ix on user_likes ( post_id, user_id , dt);
Index created.
And now here’s a PL/SQL routine that will run through the test. It will do 50,000 iterations picking a random user and random post, and exercise the above queries.
Then we’ll output the average query elapsed time, and the min/max extrema to get an idea of the response time duration.
(If you’re not familiar with PL/SQL, just skip ahead to the results in blue)
SQL> set serverout on
SQL> declare
2 type numlist is table of number index by pls_integer;
3 iter int := 50000;
4 u numlist;
5 p numlist;
6 res numlist; resrow user_likes%rowtype;
7 s1 timestamp;
8 s2 timestamp;
9 s3 timestamp;
10 delt number;
11 lo number := 999999999;
12 hi number := 0;
13 cnt int;
14 begin
15 select trunc(dbms_random.value(1,200000) )
16 bulk collect into u
17 from dual
18 connect by level <= iter;
19
20 select trunc(dbms_random.value(1,10000) )
21 bulk collect into p
22 from dual
23 connect by level <= iter;
24
25 s1 := localtimestamp;
26 for i in 1 .. iter
27 loop
28 s2 := systimestamp;
29 select user_id
30 bulk collect into res
31 from user_likes
32 where user_id = u(i);
33 delt := extract(second from localtimestamp - s2);
34 if delt < lo then lo := delt; end if;
35 if delt > hi then hi := delt; cnt := res.count; end if;
36 end loop;
37 delt := extract(second from localtimestamp - s1) + 60*extract(minute from localtimestamp - s1);
38
39 dbms_output.put_line(iter||' executions: All posts for nominated user');
40 dbms_output.put_line('=====================================');
41 dbms_output.put_line('Total: '||delt);
42 dbms_output.put_line('Avg: '||(delt/iter));
43 dbms_output.put_line('Low: '||lo);
44 dbms_output.put_line('Hi: '||hi);
45
46 lo := 999999999;
47 hi := 0;
48 s1 := localtimestamp;
49 for i in 1 .. iter
50 loop
51 s2 := systimestamp;
52 select user_id
53 bulk collect into res
54 from user_likes
55 where post_id = p(i);
56 delt := extract(second from localtimestamp - s2);
57 if delt < lo then lo := delt; end if;
58 if delt > hi then hi := delt; cnt := res.count; end if;
59 end loop;
60 delt := extract(second from localtimestamp - s1) + 60*extract(minute from localtimestamp - s1);
61
62 dbms_output.put_line(iter||' executions: All users for nominated post');
63 dbms_output.put_line('=====================================');
64 dbms_output.put_line('Total: '||delt);
65 dbms_output.put_line('Avg: '||(delt/iter));
66 dbms_output.put_line('Low: '||lo);
67 dbms_output.put_line('Hi: '||hi);
68
69 lo := 999999999;
70 hi := 0;
71 s1 := localtimestamp;
72 for i in 1 .. iter
73 loop
74 s2 := systimestamp;
75 select user_id
76 into resrow
77 from user_likes
78 where post_id = p(i)
79 and user_id = u(i);
80 delt := extract(second from localtimestamp - s2);
81 if delt < lo then lo := delt; end if;
82 if delt > hi then hi := delt; end if;
83 end loop;
84 delt := extract(second from localtimestamp - s1) + 60*extract(minute from localtimestamp - s1);
85
86 dbms_output.put_line(iter||' executions: Lookup single post for a nominated user');
87 dbms_output.put_line('=======================================');
88 dbms_output.put_line('Total: '||delt);
89 dbms_output.put_line('Avg: '||(delt/iter));
90 dbms_output.put_line('Low: '||lo);
91 dbms_output.put_line('Hi: '||hi);
92
93 end;
94 /
50000 executions: All posts for nominated user
=====================================
Total: 214.157
Avg: .00428314
Low: 0
Hi: .246
50000 executions: All users for nominated post
=====================================
Total: 2602.467
Avg: .05204934
Low: .019
Hi: .371
50000 executions: Lookup single post for a nominated user
=======================================
Total: 9.169
Avg: .00018338
Low: 0
Hi: .003
Lets take a moment to digest some of that information.
- You can do ~5400 single row lookups (known user/post combo) per second! (ie, less than a millisecond per query)
- Grabbing 10,000 posts for a known user will take about 4ms, and at worst 246ms
- Grabbing 200,000 users for a known post will take about 50ms, and at worst 371ms
and I’m doing this on a 4year old desktop PC!
So there we go. You can see that even as we scale to billions of rows, the compact branch structure of B-tree indexes means very efficient data access to data. When the volume of rows needed by an index is small (and in this case, I’m even treating 200,000 rows as small!), then in most circumstances, the overall size of the table is not an issue.




Leave a Reply